

مطالبی که میخوانید حاصل ذهن مغشوش یک دانشجوی کامپیوتر بوده و مسئولیت هرگونه خطای احتمالی به عهده ساکنین سیاره "کپلر ۶۹ سی" می باشد!
چگونه با حذف حافظه مشترک، صدها هزار درخواست در ثانیه را پردازش کردیم
محصول CDN ابر آروان در هر ثانیه صدها هزار درخواستِ متعلق به دهها هزار دامنه مختلف را دریافت میکند و هر کدام از این درخواستها براساس تنظیماتِ دامنه توسط یک یا چند ماژول مختلف پردازش میشوند (برای مثال ماژول فایروال، Rate Limit و ...). پردازش این حجم بالا از اطلاعات نیازمند معماری مناسب و راهکارهایی برای بهبود کارایی است.
معماری فعلی
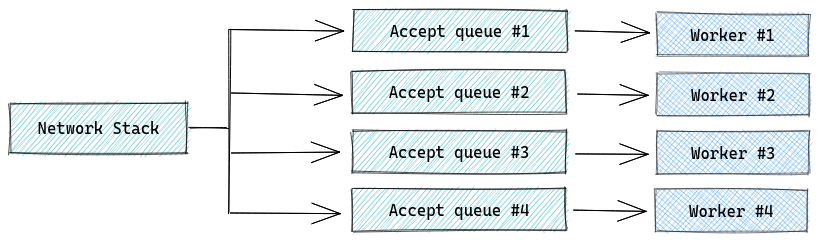
در معماری کنونی به تعداد هستههای منطقی CPU در سیستم، Nginx Worker داریم که برای استفاده بهینه از منابع و دستیابی به بیشترین بهرهوری سعی میکنیم تا حد امکان مستقل از یکدیگر عمل کنند. متناسب با هر worker یک accept queue مستقل داریم و پردازش هر درخواست از ابتدای برقراری کانکشن تا ارسال جواب به درخواستدهنده و بسته شدن، در یک worker صورت میگیرد.
مکانیزم فعلی nginx به گونهای است که workerها سوکتهای جداگانهای در حالت SO_REUSEPORT باز میکنند؛ به صورت پیشفرض در کرنل لینوکس برای هر چهارتایی از IP و Port مبدا و مقصد مقدار Hash محاسبه شده و بر اساس آن پکتها به یکی از این workerها هدایت میشوند.
چالش
ماژولها برای پردازش هر درخواست به دادههایی نیاز دارند که باید بین تمام یا بخشی از workerها به اشتراک گذاشته شوند. بخش زیادی از این دادهها (مانند تنظیمات دامنهها) read-intensive هستند و میتوان با مکانیزم RCU (Read - Copy - Update) آنها را بهصورت non-blocking به اشتراک گذاشت. بخش دیگر، دادههای تغییر پذیرند (مثل شمارندهی ماژول Rate Limit) که در زمان کوتاه بارها و بارها ممکن است مقدارشان تغییر پیدا کند.
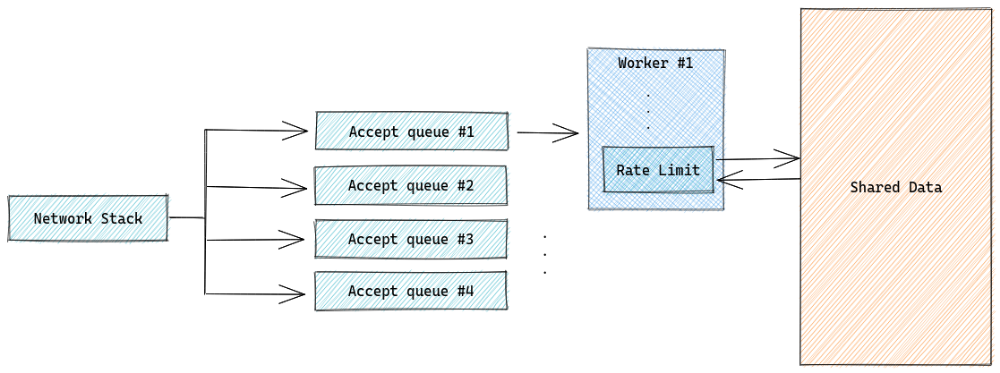
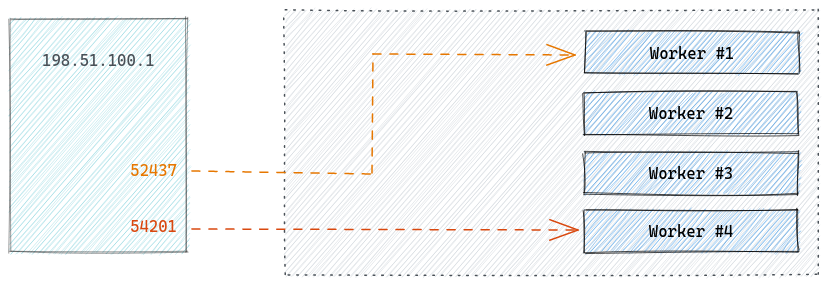
برای مثال، فرض کنید کلاینتی با آدرس 192.51.100.1 درخواستی ارسال کند؛ درخواستهایی با پورتهای مختلف (رفتار مرورگر) منجر به تولید hashهای متفاوت و درنتیجه هدایت آن درخواست به worker جداگانهای میشود. از طرف دیگر، همانطور که بالاتر اشاره شد هر worker یک پراسس جداگانه و شامل تمام ماژولها ست. از آنجایی که هر درخواست به worker جداگانهای هدایت شده نیاز به مکانیزمی برای به اشتراک گذاشتن دادههای آنها داشتیم (برای مثال در ماژول Rate Limit شمارندههایی بر اساس IP هر درخواست را به اشتراک بگذاریم).
تلاش اول؛ اشتراک گذاریِ دادهها
در ابتدا استفاده از Redis و ابزارهای مشابه برای نگهداری این دادهها بررسی شد که با کارایی مورد نظر خیلی فاصله داشت. در واقع نیاز بود تا متناسب با هر درخواست، از Redis سوال بپرسیم و داده مناسب را بگیریم؛ در بهترین حالت با فرض اینکه هر کانکشن تنها یک درخواست داشته باشد، با توجه به ترافیک بالای CDN (۱۰۰ تا ۲۰۰ هزار کانکشن همزمان)، درخواست به نودِ Redis تاخیری در حدود دهها تا صد میلیثانیه به وجود میآورد.
در قدم بعدی این مساله را با استفاده از یک حافظه مشترک (Shared Memory) حل کردیم؛ نتیجه بسیار بهتر شد اما به اندازهی کافی بهینه نبود. درواقع در لحظات اولیه یک حمله DDoS این دادههای تغییر پذیر با نرخ بسیار بالایی تغییر میکنند، استفاده از lock روی بخشی از مموری در این زمان درخواستهای سالم را هم تحت تاثیر قرار میدهد، که مستقل از شیوه طراحیِ حافظه مشترک (blocking / lock-free) باعث افت کارایی میشد.
تلاش دوم؛ تغییر معماری
استراتژی کرنل برای توزیع بار (محاسبه hash از چهارتایی IP و Port مبدا و مقصد) باعث میشد در حملات، درخواستهای مخرب به workerهای مختلف هدایت شوند و lock شدن حافظه مشترک اتفاق بیفتد. پس ایده بعدی تغییر نحوه توزیع بار بود به صورتی که نیاز به هرگونه حافظه مشترک از بین برود و از سختافزار حداکثر بهره را ببریم. امکان تغییر شیوه این توزیع بار با نوشتن یک برنامه eBPF از ورژن ۴.۵ کرنل برای UDP و ۴.۶ برای TCP ارائه شده.
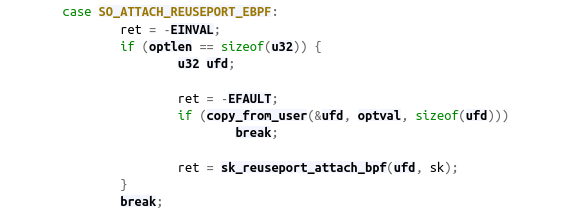
تصمیم گرفتیم پکتها را بر اساس fingerprint دیگری بین workerها توزیع کنیم تا هر کلاینت مشخص همیشه به یکی از آنها متصل شود. حافظه مشترک را در تمام ماژولهای امنیتی که باید با حملات مقابله کنند حذف و همینطور برای اینکه از سختافزار بیشترین بهره را ببریم، تسکهای پردازشی را از تسکهای منطقی جدا کردیم.
در nginx تغییراتی انجام دادیم تا برنامه eBPF که برای این کار نوشته بودیم را به سوکتهای با آپشن SO_REUSEPORT متصل کند.
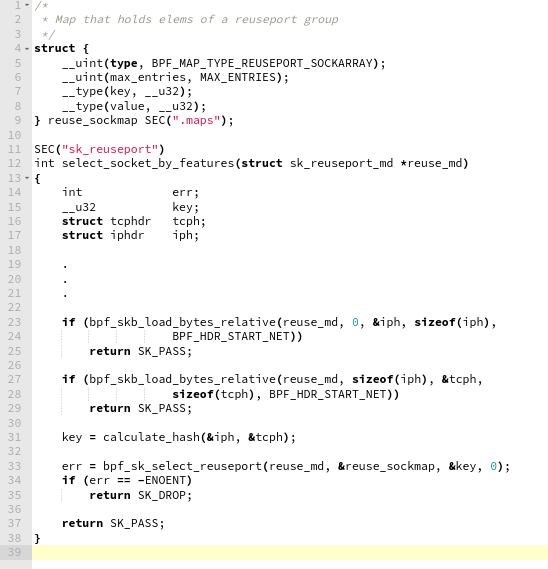
یک آرایه از سوکتهای listen شده در reuse_sockmap نگهداری میکنیم که هنگام بالا آمدن nginx مقداردهی میشود؛ هر درخواست در مرحله socket lookup به این برنامه eBPF میرسد و به کمک یک تابع hash به یکی از سوکتهای آرایه هدایت میشود.
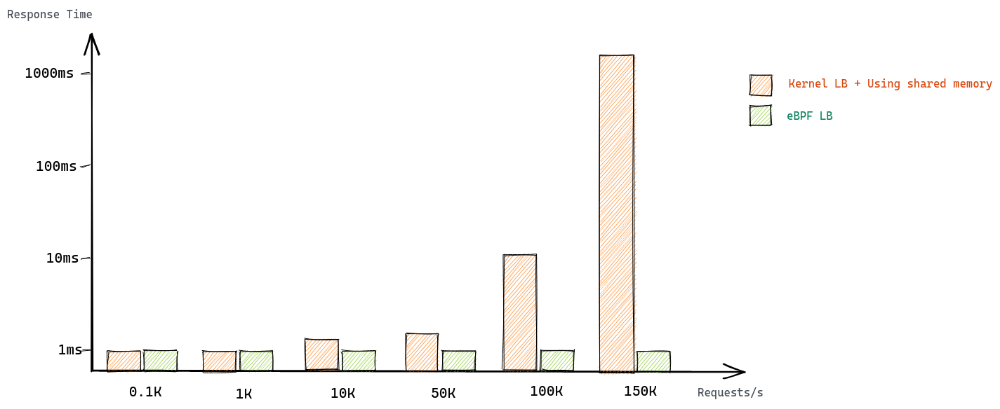
با توجه به نمودار بالا که مقایسهای از بنچمارک در دو حالت: ۱. استفاده از لودبالانسر پیشفرض کرنل و داشتن حافظه مشترک و ۲. استفاده از لودبالانسر eBPF و تغییر شیوه توزیع بار است، در حالت دوم با افزایش تعداد درخواستها تفاوت محسوسی در Response Time رخ نمیدهد.
جمعبندی
بهطور کلی اگر سرویسدهندهای در ابعاد یک CDN هستید باید در حالت عادی هم استراتژیهایی برای توزیع یکنواختِ load روی هستههای CPU داشته باشید و موضوع را به طور دائم مونیتور کنید. به این دلیل که سشنهای درازمدتِ TCP ممکن است بار را از حالت تعادل بسیار دور کنند یا اگر لودبالانسرِ socket یا مدل polling کرنل را patch میکنید به شکل مضاعف باید نگران یکنواختی این توزیع باشید و برای سناریوهای مختلف راهحل داشته باشید. همچنان که هر کدام از این تغییرات نباید سشنهای TCP یا پروتکلی مثل QUIC را در آینده مختل کنند.
چطور در لاراول به شکلی درست کوئری خود را بر اساس URL Query String فیلتر کنیم
مجازی سازی I/O یا virtio چگونه کار میکند
کاهش داونتایم (Down Time): روایت دومین سالگرد استقرار Masakari در زیرساخت ابری ما