

سالک .[ ل ِ ] (ع ص ، اِ) مسافر و راه رونده. / a3dho3yn.ir
ما از Git Flow پیروی نمیکنیم!
قبلتر در مقدمهی نوشته «هدفگذاری OKR دولا دولا نمیشه» درباره «حزبِ بار» (Cargo Cult) و تقلید کورکورانه از ایدههایی که هر از چند گاهی مد میشن نوشتم. یکی دیگه از این مدها (و تقلیدهای کورکورانه) رو میشه در Git Flow دید. جوری که خالق این روش در سال ۲۰۲۰ نوشت:
در ده سال گذشته، git-flow بسیار بین تیمهای نرمافزاری محبوب شده تا جایی که برخی با آن مثل یک استاندارد —و متاسفانه مثل یک عقیده دینی یا نوشدارو— رفتار میکنند.
در این نوشته توضیح میدم که Git Flow چیه، چه مشکلاتی داره و ما چه راهحلی رو پیش گرفتیم.
ایده Git Flow در خلاصهترین حالت ممکن
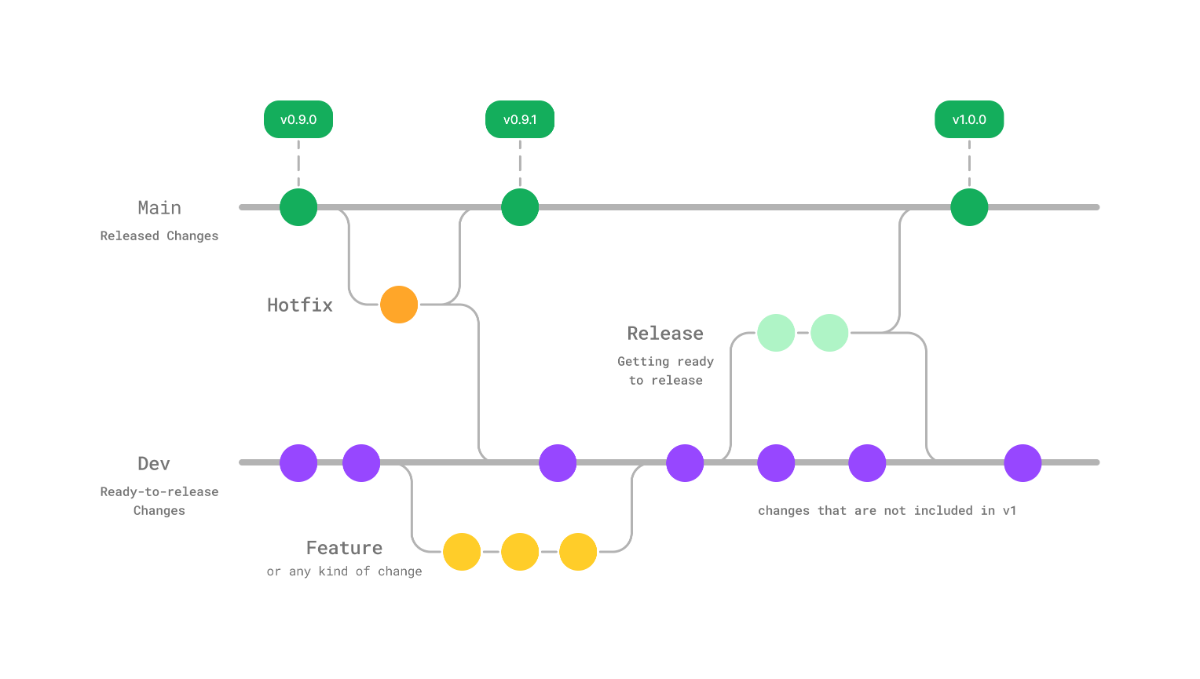
برای جلوگیری از هرجومرج در هنگام استفاده از گیت (git) در یک تیم، روشهای کاری مختلفی توصیه شدن. هر روش (workflow)، مشخص میکنه که چه وقت و چطور باید از شاخهها (branch) برای مدیریت تغییرات استفاده کنیم. روش Git Flow که سال ۲۰۱۰ معرفی شده، پیشنهادش اینه که دو شاخه با عمر طولانی داشته باشیم:
- شاخه اصلی (main): سر (HEAD) این شاخه، آخرین نسخه آماده انتشار (production-ready) رو نشون میده
- شاخه توسعه (dev): آخرین تغییرات رو —که میتونن در نسخه بعدی قرار بگیرن— در بر داره. به بیان دیگه، محل تجمیع قابلیتهای (feature) توسعه یافتهست.
و چند «مدل» شاخه کمکی با عمر کوتاه:
- قابلیت جدید (feature): برای اضافه کردن هر قابلیت جدید به نرمافزار، یه شاخه جدید از dev میگیریم و بعد از اتمام کار روی اون قابلیت، این شاخه رو با dev ادغام (merge) میکنیم.
- نسخه (release): آمادهسازی یه نسخه از برنامه.
وقتی توسعه قابلیتهای مورد نظر برای یه نسخه تمام شد، از dev یه شاخه میگیریم و بعد از انجام تستها و رفع مشکلات، و انجام کارهایی مثل بهروزرسانی شماره نسخه (version number) در کد، این شاخه رو در main ادغام میکنیم (به عنوان نسخه آماده انتشار) و برچسب (tag) میزنیم و در نهایت در dev هم ادغام میکنیم. - تعمیر سریع (hotfix): برای رفع مشکل نسخه عملیاتی (production)، از main یه شاخه میگیریم و بعد از برطرف کردن مشکل، تغییرات رو هم در main و هم در dev ادغام میکنیم.
در نظر داشته باشین که از هرکدوم از این مدلها ممکنه چندین شاخه وجود داشته باشه.
دههات گذشته¹ Git Flow!
خالق git flow در ادامهی بهروزرسانی سال ۲۰۲۰ مقالهاش نوشته:
در این ۱۰ سال [که از معرفی git flow میگذرد]، گیت دنیا را تسخیر کرده و اغلب پروژههای نرمافزاری —لااقل در حباب اطراف من— به سمت برنامههای وب رفتهاند. این برنامهها معمولاً به طور پیوسته تحویل میشوند (continuous delivery)، عقبگرد (rollback) ندارند، و نیازی به پشتیبانی از چند نسخه بهطور همزمان نیست.
این مدل نرمافزار، چیزی نیست که من موقع نوشتن این روش در ذهن داشتم.
علاوه بر خود مرحوم (که پیروانش معتقدن غلط کرد)، که در مقالهها و گفتگوهای متعدد، مشکلات مختلفی برای این روش کاری گفته شده (مثل اینجا، و اینجا). مهمترین مشکل از دید ما، پیچیدگی غیرضروری این روش بود. یعنی از خودمون پرسیدیم: این همه اضافهکاری برای چیه؟ چرا باید dev و main جدا باشه؟ ما که نسخههای مختلف نداریم، چه نیازی به release branch داریم؟ و ... . پس روش کاریمون رو اینطوری بازتعریف کردیم:
- فقط یک شاخه دائمی وجود داره: main
آخرین تغییرات به این شاخه اضافه میشن و انتظار میره این تغییرات قابل انتشار باشن.
تغییراتی که در این شاخه قرار میگیرن، بعد از اجرای تست خودکار در محیط staging قرار میگیرن.
این شاخه حفاظتشده (protected) است و تغییرات فقط از طریق merge/pull request میتونن بهش اضافه بشن. - برای توسعه، از feature branchها کمک میگیریم
این شاخهها موقتی هستن و بعد از اتمام توسعه، حذف میشن.
در واقع feature اسم مصطلحه و ممکنه کارهایی از جنس رفع مشکل (bug fix)، بازسازی (refactoring)، و نظایرش انجام بشه. میشه اسم شاخه رو متناسب با کاری که انجام میشه انتخاب کرد، یا حتا اسم کلیتر (مثل dev) گذاشت. - آخرین نسخه منتشر شده رو با tag/release مشخص میکنیم.
با ایجاد tag، فرآیند استقرار در محیط عملیاتی (production) به طور خودکار شروع میشه.
ایجاد tag در کنار چند کار دیگه تقریباً خودکار انجام میشه: اسکریپت bump version رو اجرا میکنیم که شماره نسخه و فایل CHANGELOG رو بهروز میکنه، و بعد اضافه کردن تغییرات به main، یه tag/release ایجاد میکنه. - اگر نیاز به hotfix باشه، از tag نسخه مورد نظر یه شاخه میگیریم و بعد از رفع مشکل، یه تگ جدید میسازیم و در نهایت شاخه hotfix رو در main ادغام میکنیم.

چرا سراغ Trunk-based Development نرفتیم؟
اگرچه تا حد خوبی از مدل چند شاخه و پیچیدهی git flow دور و به Trunk-based Development نزدیک شدیم، امّا هنوز برای استانداردهای افراطی TBD آمادگی (و علاقهمندی!) نداشتیم. برای اینکه بشه با اطمینان تغییرات رو انقدر سریع یکی کرد و بالا فرستاد، باید اتکاپذیری فرآیندهای تست و استقرار خودکار زیاد باشه، یا باید به جای حل کردن merge conflict، روی این وقت بذاریم که چطور قدمهای کار رو تعریف کنیم که ضمن اعمال تغییرات کامل نشده، بقیه اجزای سیستم دچار مشکل نشن و الی آخر. درسته ما هم علاقهمندیم عمر شاخههای توسعه طولانی نباشه، امّا اصرار به اینکه کارها طی چند ساعت انجام بشه (و بالتبع عمر شاخهها همین اندازه باشه) رو زیادهروی میدونم. یا برخلاف دیدگاههای افراطیتر درباره CI، فکر نمیکنم که نباید از branch استفاده کرد و/یا نباید از main دربرابر اعمال مستقیم تغییرات حفاظت کرد.
به بیان دیگه، TBD داره مسائلی رو حل میکنه که برای ما وجود نداره و تو این شرایط، استفاده از این روش، مثل استفاده از Git flow پیچیدگی غیرضروری تحمیل میکنه. شاید در آینده شرایط و مسائلمون تغییر کرد و ما هم این روش رو پیش گرفتیم ?♂️
و در آخر...
بهترین توصیه، همونیه که خالق گیت-فلو گفته:
... همیشه به خاطر داشته باشید نوشدارو وجود ندارد. شرایط خودتان را در نظر بگیرید.
به جا اینکه دنبال فیسبوک و گوگل و بقیه راه بیافتید، یا مرعوب جملاتی مثل «Git Flow: یک مدل موفق کاری برای Git» یا «بدون trunk-based development شما اصلاً Continuous Integration ندارید» بشید، شرایط خودتون رو در نظر بگیرید، مدلهای مختلف رو ببینید، و راهی که براتون مناسبه رو انتخاب کنید.
¹ دیالوگ سلحشور تو آژانس شیشهای که به حاج کاظم میگفت: «دههات گذشته مربی»
Distributed Tracing And Jaeger
تغییرات نرم افزاری لازم قبل از آغاز سال ۱۴۰۲
قهرمان خاموش یک مایگریشن موفق: AM-ROUTE