

مجازی سازی I/O یا virtio چگونه کار میکند

حوزه ی فعالیت شرکت ما کلاده. ما از KVM و QEMU برای مجازی سازی استفاده میکنیم. تو این پست سعی میکنم معماری و تئوری قضیه رو تا حدودی توضیح بدم. بعد اگر عمری بود و با استقبال پرشکوهتون مواجه شد :) وارد ریز قضایا میشیم مثل بررسی استراکچر vring ها و بررسی یکی از virtio_driver های پیاده شده در لینوکس و ترنسپورت PCI/PCIe و بررسی بک اند چارچوب virtio
یه ذره مقدمه
اصلا KVM چیه؟
هرقدر جلوتر رفتیم اهمیت مجازی سازی بیشتر و بیشتر شد تا جایی که CPU سازها گفتن آقا اینجوری نمیشه دیگه ما باید در سطح سخت افزار از مجازی سازی پشتیبانی کنیم. اومدن و یک سری اکستنشن اضافه کردن به معماری شون. ینی خلاصه بخوام بگم الان دیگه سخت افزار یا به طور خاص CPU میدونه که داره کد یک ماشین مجازی رو اجرا میکنه. حالا این قابلیت رو چجوری مدیریت کنیم؟ KVM یه ماژول کرنل لینوکسه که برای ما این کار رو انجام میده فارغ از مدل و معماری CPU . مثل خیلی جاهای دیگه در حوزه ی نرم افزار، KVM تفاوت ها و پیچیدگی ها رو از کاربر پنهان میکنه. KVM به صورت یک device file خودش رو به کاربر نشون میده. کاربر مثل خیلی از device file های دیگه اول باید این فایل رو open کنه و بعد از طریق ioctl باهاش حرف بزنه
حالا چه کارایی ازش برمیاد این KVM؟
خب خیلی کارا. KVM پردازنده ی مجازی رو کنترل میکنه. مدیریت حافظه ی ماشین مجازی از کارای دیگه ایه که ازش برمیاد. اما اون قابلیت هایی که تو این بحث مجازی سازی I/O برای ما مهمه یکی تزریق interrupt به ماشین مجازیه و اون یکی کنترل دستورالعمل هاییه که ماشین مجازی اجرا میکنه. ینی مثلا فرض کنید ماشین مجازی میخواد فلان رجیستر CPU رو تغییر بده یا تو فلان قسمت از حافظه اش یه چیزی بنویسه و ما میخوایم از این فعالیت ها مطلع بشیم. اگه یادتون باشه گفتیم کاربر KVM رو به صورت یک device file میبینه. قبل از راه اندازی ماشین مجازی کاربر از طریق همین دیوایس فایل به KVM میگه که مثلا اگه ماشین مجازی خواست روی فلان رجیستر یا فلان آدرس حافظه تغییری بده به من بگو. KVM این تنظیمات رو با توجه به معماری CPU ست میکنه. بعد وقتی ماشین مجازی خواست این دستورالعمل ها رو اجرا کنه کنترل از ماشین مجازی به ماشین میزبان منتقل میشه. به این اتفاق میگن vm-exit .
KVM چک میکنه که آیا کاربر میخواد از این اتفاقی که افتاده باخبر بشه یا نه. اگه جواب آره بود کنترل از سیستم عامل میزبان به کاربری که خواسته از این تغییرات مطلع بشه منتقل میشه
این وسط نقش QEMU چیه؟
با این که یه عالمه کار از KVM برمیاد اما به تنهایی نمیتونه یک ماشین مجازی کامل رو پیاده کنه. یک ماشین مجازی کامل نیاز به تجهیزات جانبی داره مثل کارت شبکه یا تجهیزات ذخیره سازی. این جای خالی رو QEMU پر میکنه
دو روش برای پیاده سازی I/O در محیط های مجازی:
قبل تر اشاره کردم که نقش QEMU مجازی سازی تجهیزات یک سیستمه. خود QEMU به صورت یک پراسس معمولی در سیستم عامل میزبان ظاهر میشه. بخشی از address space ش رو در اختیار ماشین مجازی قرار میده و این میشه حافظه ی RAM فیزیکال ماشین مجازی:
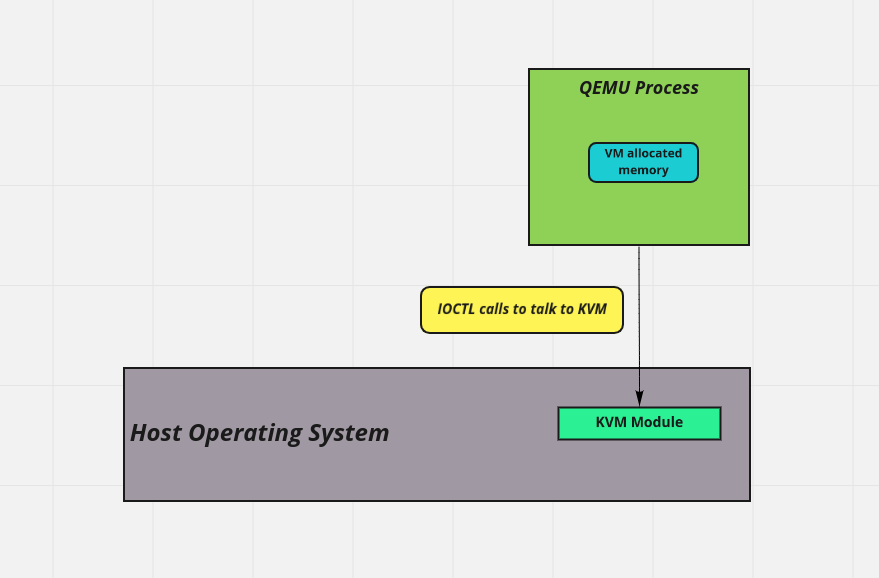
اینم توجه داریم که اساسا QEMU میتونه تمام فضای RAM اختصاص داده شده به ماشین مجازی رو ببینه. اما I/O چی؟ یک روش اینه که QEMU به طور کامل مثلا کارت شبکه رو شبیه سازی کنه. تو این حالت سیستم عامل مهمان اصلن نمیدونه که داره به صورت مجازی اجرا میشه و نیازی به هیچ تغییری نداره. یادتون هست گفتم KVM میتونه یک سری تنظیماتی رو روی CPU ست کنه که در صورت اجرای بعضی دستورات خاص کنترل به ماشین میزبان برگرده؟ به اینا میگیم trap. حالا فرض کنید سیستم عامل ماشین مهمان میخواد یک سری فریم، پکت یا هر چیزی تو این مایه رو بفرسته جایی. برای انجام این عملیات نیاز داره یک سری اینستراکشن خاص روی CPU اجرا کنه که اون هم به نوبه ی خودش با مثلا کارت شبکه باقی قضیه رو جلو میبره. اتفاقی که اینجا میفته اینه که این دستورات trap میشن. کی trap میکنه؟ KVM بر اساس تنظیماتی که QEMU قبل از ران کردن ماشین مجازی بهش داده. KVM و QEMU یک قسمتی از حافظه ی میزبان رو با هم شریک میشن. KVM اطلاعات و دستورات trap شده رو میگذاره تو همین حافظه ی اشتراکی و بعد کنترل منتقل میشه به QEMU. QEMU به نوبه ی خودش این طلاعات رو پاس میده به دستگاهی که شبیه سازی کرده. دستگاه شبیه سازی شده عملیات رو انجام میده و نتیجه رو میگذاره توی همون حافظه ی اشتراکی و KVM رو از این اتفاق باخبر میکنه. KVM در نهایت نتیجه ی عملیات رو در حافظه ی ماشین مهمان قرار میده و کنترل منتقل میشه به ماشین مهمان. به این روش میگن full virtualization:
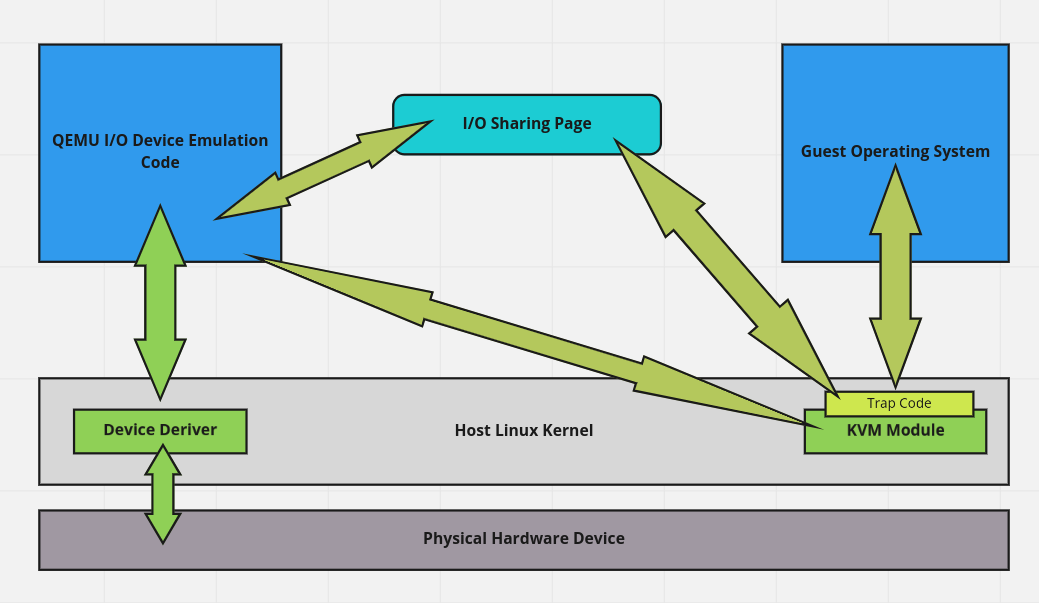
از مزایای این روش میشه اینا رو گفت:
- نیازی به تغییر در سیستم عامل میزبان وجود نداره
- بعضی از پروژه ها نیاز دارن با دستگاه های قدیمی کار کنن و خب این دستگاه ها به سادگی پیدا نمیشن. با این روش به راحتی میشه اون دستگاه رو شبیه سازی کرد
اما معایبش چیه:
- مسیر انجام عملیات طولانیه
- اطلاعات چندین و چند مرتبه کپی میشه
- کانتکست سویچ های زیاد (از مهمان به KVM، از KVM به QEMU، از QEMU به سیستم عامل میزبان...)
به طور خلاصه میشه گفت که مشکل اصلی این روش پرفورمنسه.
اما در مقابل full virtualization یه مفهموم دیگه ای داریم به اسم paravirtualization. تو این حالت سیستم عامل مهمان میدونه که داره به صورت مجازی اجرا میشه و برای انجام عملیات I/O با میزبان و هایپروایزر همکاری میکنه. virtio چارچوبیه که paravirtualization رو برای عملیات I/O پیاده سازی و استاندارد میکنه.
حالا چطور کار میکنه؟ بذارید اول یه کم از اجزا و ویژگی های چارچوب virtio بگم:
- سیستم به دو قسمت تقسیم شده: فرانت اند و بک اند. فرانت اند در مهمان پیاده سازی میشه و بک اند در هایپروایزر یا سیستم عامل هاست. به فرانت میگیم virtio driver و به بک میگیم virtio device
- بک اند یا همون device باید بتونه قابلیت هایی رو که پشتیبانی میکنه به فرانت اطلاع بده (Device's feature bits) مثلا اگه کارت شبکه باشه اینکه آیا میتونه محاسبه ی checksum رو آفلود کنه روی سخت افزار اصلی یا نه CPU باید این عملیات رو انجام بده
- فرانت باید راهی داشته باشه که بتونه به بک کامند بده و از وضعیتش با خبر بشه (Status bits)
- فرانت باید بتونه از تنظیمات بک باخبر بشه (Configuration space)
- فرانت و بک باید بتونن هم رو از یک سری اتفاقات باخبر کنن. تو مثال کار شبکه فرانت باید بتونه به بک اطلاع بده که یه سری فریم آماده برای ارسال داره (available frames) و بک متقابلن باید بتونه به فرانت اطلاع بده که فریم برای تحویل داره (used frames)
- بسته به دستگاهی که قراره شبیه سازی بشه صفر تا چند صف یا virtq برای تبادل انبوه اطلاعات
- یک بستر برای تبادل اطلاعات بین فرانت و بک (transport specific interface to the device)
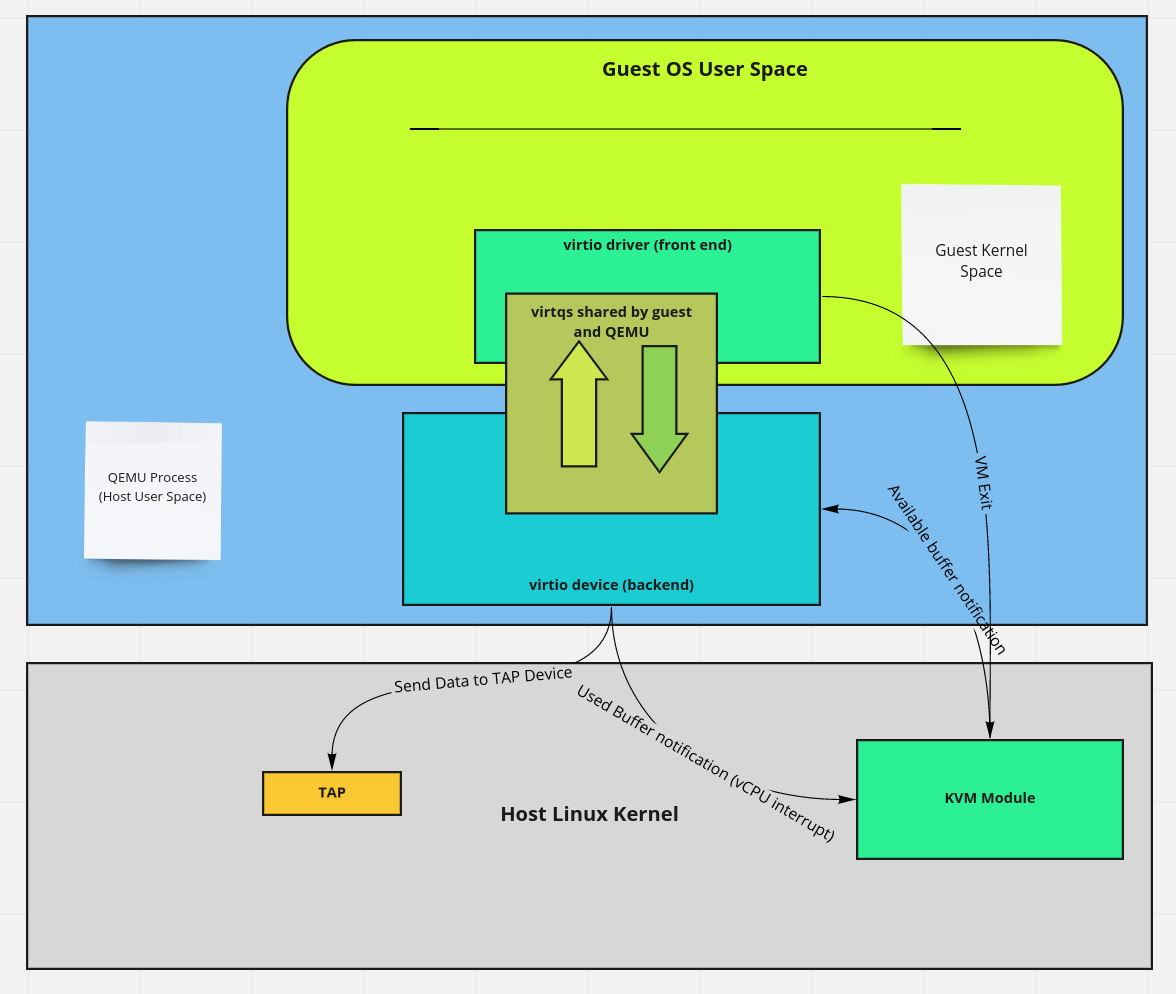
اگه یادتون باشه گفتیم QEMU میتونه تمام فضای RAM اختصاص داده شده به ماشین مجازی رو ببینه چون یک پراسسه و RAM مهمان در واقع در address space پراسس QEMU قرار داره. اینم یادتون هست که میتونیم از KVM بخواهیم اگر مهمان خواست تو فلان قسمت حافظه بنویسه به ما اطلاع بده. فعلا هم همین اندازه از من قبول کنین که یک سری آدرس های خاص در مموری مهمان برای تبادل اطلاعات مربوط به تنظیمات و استتوس بک در نظر گرفته شده که به صورت کلی بهشون میگیم control plane. اون قسمت از سیستم هم که برای تبادل انبوه اطلاعات استفاده میشه ینی همون صف ها یا virtq ها رو میگیم data plane. از قبل به KVM گفتیم که اگر مهمان خواست اطلاعات اون قسمت از مموری رو که مربوط به استتوس بک میشه تغییر بده کنترل رو منتقل کنه به QEMU ینی اینجا ابزار فرانت برای مطلع کردن بک از اتفاقات vm-exit عه. حالا همون سناریوی ارسال فریم از سیستم عامل مهمان رو در نظر بگیرید. فرانت یک بافر رو که یکی از virtq هایی باشه که در اختیارشه با دیتای مورد نظرش پر میکنه و بعد سعی میکنه استتوس بک رو تغییر بده. اینجا vm exit رخ میده و کنترل متقل میشه به KVM. KVM چک میکنه که آیا این آدرس همون آدرسیه که QEMU گفته بود یا نه. اگه آره کنترل منتقل میشه به QEMU. QEMU به اطلاعات ارسالی از مهمان دسترسی داره. چطور؟ چون مموری مهمان بخشی از address space خودشه. پس میتونه اطلاعات رو بخونه و بعد کاری که لازمه رو باهاشون انجام بده و در نهایت نتیجه رو توی یک بافر دیگه که باز یک virtq باشه قرار بده. در نهایت QEMU از KVM میخواد که با یک interrupt مهمان رو از اتفاق رخ داده با خبر کنه. پس اینجا مکانیزم بک برای مطلع کردن فرانت از پایان عملیات vCPU interrupt میشه.
پیام اخلاقی
خب اگر الان یک مقایسه با روش قبلی بکنیم متوجه میشیم که کپی دیتا کمتر شده و همینطور کانتکست سویچ هایی که در مسیر انجام عملیات باید انجام بشه. اینم توجه داریم که بک اند میتونه کاملا یک پیاده سازی متفاوتی داشته باشه بدون نیاز به تغییر فرانت. راستش یک روش دیگه ای برای پیاده سازی بک وجود داره و اونم این که کلا بیاریمش تو فضای کرنل هاست که دیگه نیازی به کانتکست سوییچ از KVM به QEMU نداشته باشیم. سعی میکنیم تو پست های بعدی این روش رو توضیح بدم
مطلبی دیگر از این انتشارات
توسعه نرمافزار چابک با نگاه «محصولمحور»
مطلبی دیگر از این انتشارات
چطور در آروانکلاد با ساختمانداده و الگوریتمهای بهینه مشکل حجم زیاد اطلاعات را حل کردیم
مطلبی دیگر از این انتشارات
آیا نوشتن تست، فرآیند توسعه نرمافزارتان را واقعا کندتر میکند ؟