

سالک .[ ل ِ ] (ع ص ، اِ) مسافر و راه رونده. / a3dho3yn.ir
مدیریت حادثه؛ بخش اول: رقصیدن با خرس
این مجموعه نوشته، برگرفته از روش ما در ابرآروان برای مدیریت حادثه است. در این قسمت، به پیشزمینه و اهمیت موضوع و رویکرد درست به حادثه میپردازم و قسمتهای بعد، راهنمای آمادگی برای حادثه، پاسخ به حادثه و کالبدشکافی خواهد بود. باید تاکید کنم که این روشها، اغلب اختراع ما نیست و دنبالهروی روشها و/یا شرکتهای شناخته شده بودیم.
روزهای پایانی اسفند ۱۳۹۹، در دو شب متوالی مشکلی غیرعادی در سوییچهای آروان در دیتاسنتر آسیاتک (IR-THR-AT1) اتفاق افتاد و تکرار حادثه، این گمان رو تقویت کرد که مورد حمله قرار گرفتیم. اگرچه اقداماتی برای محدودیت دسترسی و جلوگیری از تکرار مشکل انجام دادیم، امّا روز سوم، مشکل تکرار و در ادامه، تبدیل به بحران شد. بحرانی که ۲۵۰۰ مشتری و ۷۰۰۰ ابرک رو تحت تاثیر قرار داد (و به ۹ درصدشون آسیب زد)، و یه ماه تقریباً تمام شرکت رو درگیر کرد.
بعد از حادثه، به این فکر افتادیم که «چطور میتونستیم واکنش مناسبتری به حادثه نشون بدیم؟». در جستجو برای تجربههای دیگران در رویارویی با حادثه، نظرمون به کتابچهی مدیریت حادثه شرکت اطلسیَن جلب شد. روایت اطلسین در این کتابچه به خوبی نشون میده که آروان اوّلین (و آخرین) مجموعهای نیست که چنین درس سختی از یه حادثه میگیره. جیم سِورینو —تیملید در اطلسین— اینطور روایت میکنه:
سال ۲۰۱۴، در پی تغییر گستردهی صنعت به سمت SaaS، مجموعه ابری اطلسین نیز در حال تکامل از یک مجموعه نرمافزار درهمتنیدهی قابل دانلود به یک سیستم ابرزی (Cloud Native) بود. این تغییری بزرگ بود و به برنامهریزی و اجرای دقیقی در سراسر شرکت نیاز داشت. یک تیم، هشت ماه روی یکپارچه کردن مدیریت گروهها و کاربران محصولات مختلف کار کرده بود تا کار مشتریان ابری سادهتر شود و به جای اینکه مجبور باشند کاربران و گروهها را در هر محصول به صورت جداگانه مدیریت کنند، تنها با یک مجموعه تنظیمات و یک رابط کاربری برای مدیریت آن روبهرو باشند.
بالاخره آماده شدیم. طی چند هفته، به مرور تغییرات را برای همهی مشتریان رونمایی (Rollout) کردیم. در ابتدا همه چیز خوب به نظر میرسید...امّا بعد یک مورد پشتیبانی جالب پیش آمد. یک مشتری مدعی شده بود که کاربرانشان محتوایی که نباید به آن دسترسی داشته باشند را میبینند. با بررسی موضوع، فهمیدیم نسخهای که منتشر کرده بودیم در بعضی موارد خاص (Edge Cases) گروهبندیها را طوری بازتنظیم کرده بود که بعضی کنترلهای دسترسی را حذف شده بودند. این مشکل، اجازه میداد بعضی از کاربران مشتریان به محتوایی که قرار بود خارج از دسترس آنها باشد، دسترسی پیدا کنند.
اگرچه مشتریان کمی را تحت تأثیر قرار داده بود، امّا به دلیل شدت و اهمیت موضوع، اولویت این مشکل را بالا در نظر گرفتیم. سریع یک اصلاحیه (Fix) منتشر کردیم...دست کم فکر میکردیم که اصلاحیه باشد (و شرط میبندم میتوانید حدس بزنید بعد چه اتفاقی افتاد). مشخص شد که آن اصلاحیه مشکل را بدتر کرده است: ما ناخواسته شدت اثر را چند ده برابر بزرگتر کرده بودیم. حالا، به جای اینکه فقط چند کاربر یا چند مشتری بتوانند به محتوای غیرمجاز دسترسی داشته باشند، هزاران کاربر از صدها مشتری در این وضعیت بودند. یک ایراد فاجعهبار در پیکربندی کنترل دسترسی بود و کاملاً قابل درک بود که بعضی از بهترین مشتریهایمان عصبانی باشند.
حادثهی ثانویه، برای چند هفته چندین تیم را درگیر کرد، چندین شب بیدار ماندیم، و همه کارکنان را —از واحد مهندسی تا روابط عمومی— به کار گرفت. برنامهریزیها بههم ریخت، تعطیلات لغو شد، و اتاقهای جلسه به عنوان «اتاق جنگ» اشغال شده بود. پس از حل مشکل و آرام شدن اوضاع، از خودمان پرسیدیم: چه اشتباهی منجر به این شد؟ چطور میتوانستیم جلوی آن را بگیریم، یا واکنش بهتری نشان بدهیم؟ چرا از حادثههای مشابه در گذشته درس نگرفته بودیم؟
تلاش مذبوحانه برای حذف حادثهها
بسیاری از سازمانها نیاز به فرآیندهای مدیریت حادثه و کالبدشکافی رو به روش مشابهی کشف میکنن: یه حادثهی بزرگ که بد پیش رفته رو تجربه کردند و بعد تصمیم گرفتند نگذارند دیگه این تجربه تکرار بشه. در این شرایط، خیلی وسوسهکننده است که فرآیندی طراحی کنیم که جلوی تمام حادثهها رو بگیره. سازمانها برای رسیدن به این هدف، گیتهای امنیتی (Safety Gates)، نقاط بازرسی (Checkpoints)، کمیته بازبینی تغییرات (CAB)، و سربارهای دیگهای رو به فرآیند طراحی، توسعه و انتشار اضافه میکنند. اگرچه این واکنش به حادثه قابل درکه، ولی واکنش درستی نیست. این قدمهای اضافه، اگر چه ممکنه در کوتاه مدت حادثهها رو کم کنه، ولی باعث کند شدن تغییرات میشه و در بلند مدت باعث میشه تغییرات پشت هم گیر کنند و تغییرات بزرگ در فاصلههای زمانی زیاد منتشر بشه، و ریسک تغییرات (و احتمال حادثه) بهمراتب افزایش پیدا کنه. نتیجه نهایی اینه که هم تغییرات و فرآیندها کند شده و هم همچنان حادثه رخ میده. خواستیم از اینور بوم (و بیتوجهی) نیافتیم، از اونور بودم (و توجه بیش از حد) افتادیم.
این حس که باید حادثهها رو کاهش بدیم، درسته؛ امّا تلاش برای رسیدن به «صفر حادثه» اشتباهه. همونطور که تنها راه صفر شدن آمار طلاق، جلوگیری از ازدواجه، تنها راه جلوگیری کامل از حادثهها هم متوقف کردن تغییراته! واضحه که این شدنی نیست؛ برای رقابت و زنده موندن در کسبوکار، باید تغییر کرد. هدف باید کاهش ریسک به شیوهای باشه که جلوی کار رو نگیره. همونطور که به جای اینکه ساخت ماشین و ساختمان متوقف بشه، کیسهی هوا و سنسور دود اختراع شد. ما هم میتونیم با به کارگیری روشهایی مثل Canary Deployment و Feature Flag ریسک تغییرات رو کم کنیم (و البته بدونیم که هیچ وقت صفر نمیشه). توضیحات بیشتر در این رابطه رو میتونین در فصل ۳ کتاب SRE گوگل با عنوان «استقبال از ریسک» بخونین.

رقصیدن با خرس
عنوان این قسمت رو از کتاب Waltzing with Bears برگرفتم. رقصیدن با خرس، پذیرفتن (یا در واقع درآغوش کشیدن!) ریسک برای رسیدن به نفع بیشتره. همونطور که جیم سورینو در پایان پیشگفتار کتابچه مدیریت حادثه نوشته:
شنیدهام که حادثه را «سرمایهگذاری برنامهریزی نشده برای اتکاپذیری (Reliability) سرویسها» تعریف میکنند. چه بخواهید، چه نخواهید، حادثهها رخ میدهند. نقش شما به عنوان مسئول فرآیند حادثه و کالبدشکافی این است که کاری کنید تا حد امکان این سرمایهگذاری کمهزینه شود (با کاهش اثر و مدت)، و حداکثر بهره را از هر حادثه ببرید (با یادگیری و کاهش ریسک).
این ایده، ایدهی محوری در مواجهه با حادثه خواهد بود و در چند مرحله، تلاش میکنیم به این اهداف برسیم:
- آمادگی برای حادثه: در سه جنبه حفاظت بیشتر (و کاهش احتمال حادثه)، شناسایی سریعتر و اقدام بهتر، آمادگیمون رو برای حادثه افزایش میدیم.
- پاسخ به حادثه: با پیروی از قواعد از پیش تعریف شده، جلوی سردرگم شدن افراد رو میگیریم، مانع از افزایش آسیب میشویم و در سریعترین زمان، مشکل رو برطرف میکنیم.
- درس گرفتن از حادثه: با فرآیند ساختاریافته، حادثه رو از همه جوانب بررسی میکنیم و با ترمیم مشکلاتی که منجر به حادثه شدند، جلوی دوباره گزیدن شدن از یک سوراخ رو میگیریم و آمادگیمون رو افزایش میدیم.
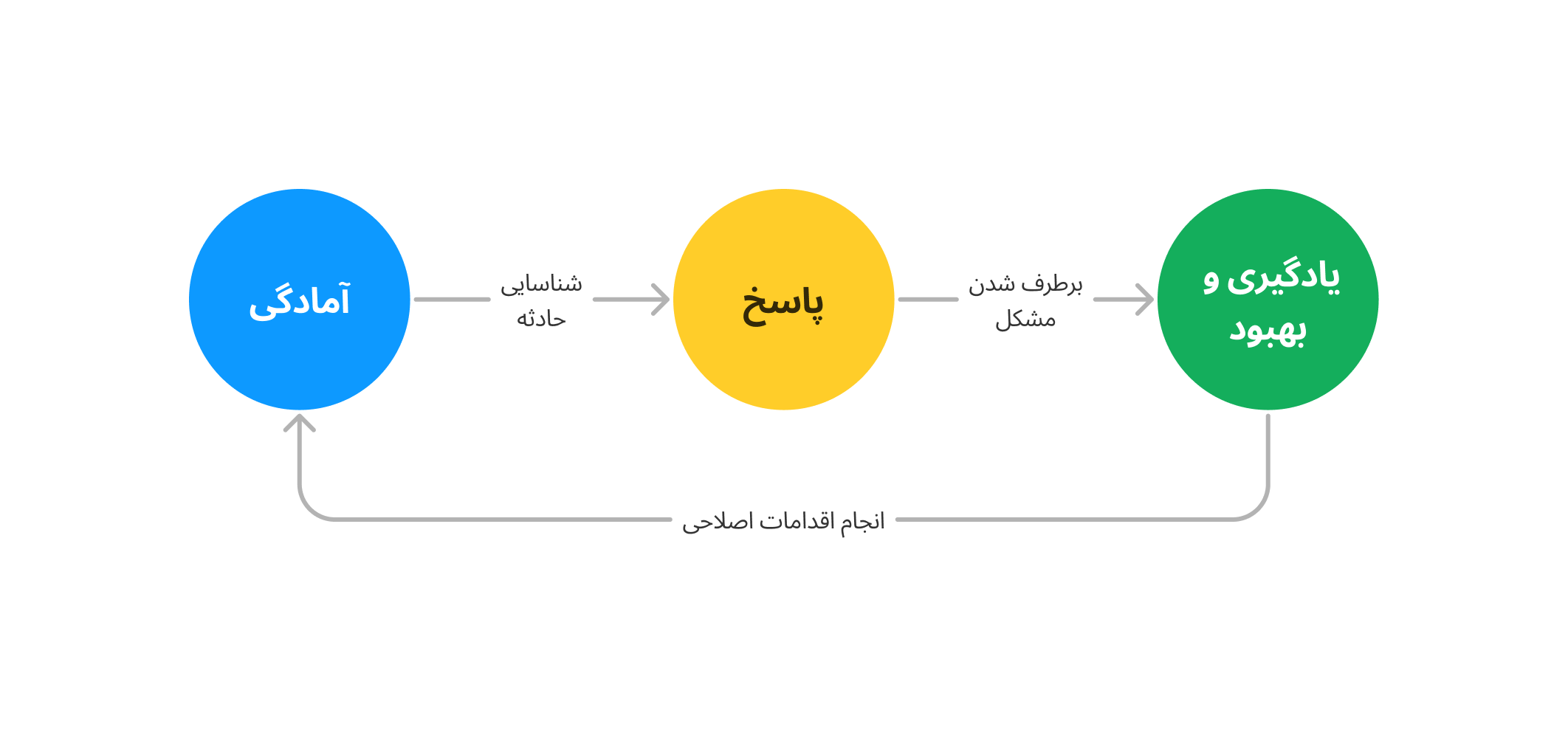
در قسمتهای بعد از این مجموعه نوشته، به طور مفصل به هر کدوم از این مراحل میپردازم. نوشتهها، همزمان که رویکرد ما در مواجهه با حادثه رو نشون میده، با این نگاه بازنویسی شدهاند که راهنمای شما برای تدوین شیوهنامه پاسخ به حادثه باشه و به همین دلیل بعضی جزییات (که بیشتر کارکرد داخلی داشتند) حذف شدند.
مطلبی دیگر از این انتشارات
Blameless is more: چالش کالبدشکافی بیسرزنش و مسئولیتپذیری
مطلبی دیگر از این انتشارات
همکاری آوین، آروان و آیو برای خلق آینده
مطلبی دیگر از این انتشارات
ما از Git Flow پیروی نمیکنیم!