

کاهش داونتایم (Down Time): روایت دومین سالگرد استقرار Masakari در زیرساخت ابری ما
تصور کنید یک روز تابستانی است. شرکت ما در اوج ترافیک کاری به سر میبرد. کاربران در حال استفاده از سرویسهای پیادهسازی شده بر بستر ابرکهای ما هستند: بعضیها در حال رزرو هتل، برخی مشغول انجام تراکنشهای مالی حساس، و گروهی دیگر سرگرم اجرای تحلیلهای پیچیده داده. همهچیز ظاهراً عالی پیش میرود تا این که ناگهان یکی از میزبانها (Host) در زیرساخت ابری ما از کار میافتد.
همانطور که میتوانید حدس بزنید، کابوسی ناگهانی همه را فرا میگیرد. کاربرانی که تا چند لحظه پیش با خیال راحت در سیستم مشغول فعالیت بودند، اکنون با خطاهای ناامیدکننده مواجه میشوند. آلرت ها(Alerts) به صدا در میان و نفر آنکال باید به سرعت فرآیند خالی کردن سرور از دسترس خارج شده رو شروع کنه.
ما پیشتر هم از ابزارها و روشهایی برای افزایش دسترسپذیری (High Availability) استفاده کرده بودیم، اما واقعیت این بود که هنگام وقوع بحران، همچنان زمان ارزشمندی صرف ریکاوری سیستم و بازگرداندن ابرکها میشد. همین لحظات حیاتی برای کاربران گران تمام میشد: تراکنشهای حساس به تعویق میافتاد و در این میان برخی کاربران ناخشنود برای همیشه از ما روی برمیگردانند. از آن بدتر، اگر این مشکل در نیمهشب رخ میداد، تا بیدار شدن نفر آنکال، دسترسی به سیستم، و آغاز فرآیند ریکاوری، زمان بیشتری از دست میرفت.
اینجا بود که نام "Masakari" وارد صحنه شد؛ ابزاری از اکوسیستم OpenStack که برای تضمین پایداری سرویسها طراحی شده است. ما تصمیم گرفتیم فرصتی به Masakari بدهیم و ببینیم آیا واقعاً میتواند ما را از این وضعیت نجات دهد یا خیر.
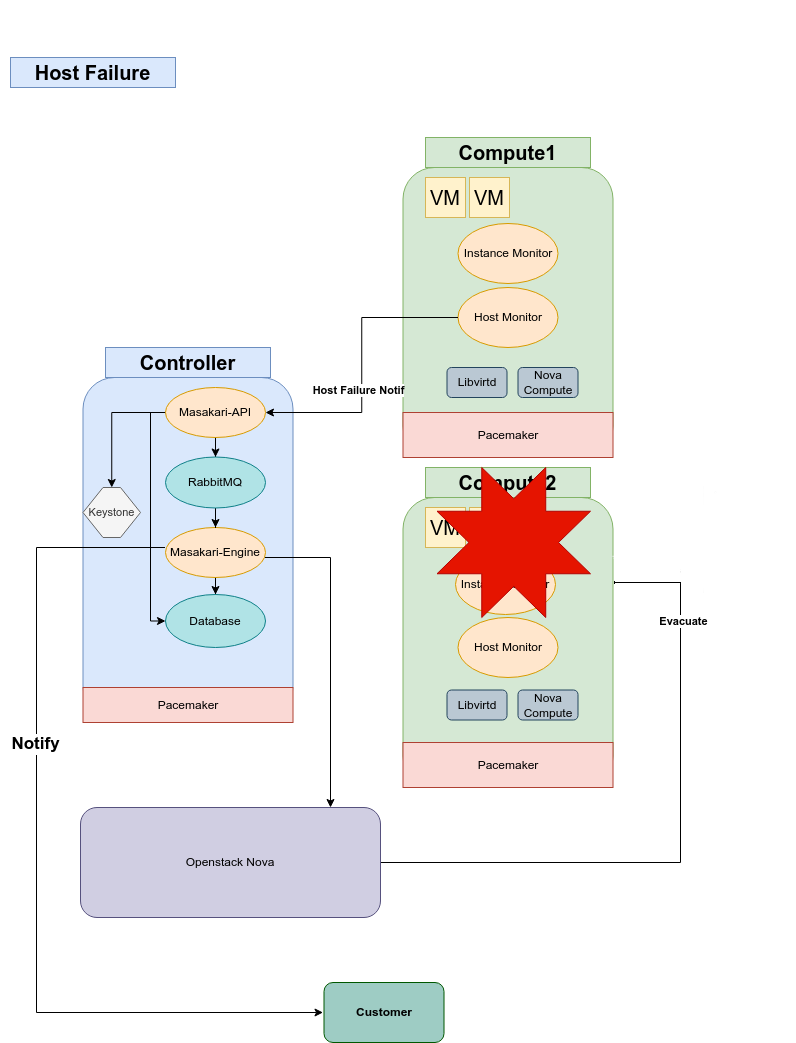
بعد از اجرای اولیه Masakari در محیط استیج (Staging) و بررسی نتایج، متوجه شدیم که برای رسیدن به عملکردی ایدهآل، نیاز داریم آن را متناسب با شرایط زیرساخت خودمان سفارشیسازی کنیم. در واقع، Masakari بهصورت پیشفرض قابلیتهای فراوانی دارد، اما هر محیط ابری ویژگیها، محدودیتها و اولویتهای خاص خود را دارد. همین موضوع باعث شد پس از اولین تستها، به جای استقرار مستقیم در محیط عملیاتی، کمی دست نگه داریم و Masakari را با دقت بیشتری بررسی و بهینه کنیم.
برای مثال، به دلیل برخی محدودیت ها، نیاز داشتیم که فرآیندهایی جهت اطمینان از داون بودن هاست اضافه کنیم. در بخش TaskFlow نیز لازم بود گامهای ریکاوری را با جزئیات بیشتری بهینه کنیم تا مطمئن شویم در هنگام رخداد خرابی، دقیقاً همان مراحلی اجرا میشود که میخواهیم.
آشنایی با Masakari: قهرمان لحظات بحرانی
Masakari یک سرویس در OpenStack است که هدف اصلیاش حفظ پایداری ماشینهای مجازی و جلوگیری از وقفه در سرویسهای حیاتی میباشد. این ابزار بهطور هوشمند رخدادهای خرابی را شناسایی میکند و بدون نیاز به مداخله نیروی انسانی، فرآیند ریکاوری و بازگرداندن سرویسها را آغاز مینماید. در واقع، Masakari نقش یک ابرقهرمان پشت صحنه را بازی میکند و در لحظات بحران، با ورود سریع و خودکار، مانع از توقف چرخ کسبوکار دیجیتال ما میشود.
زیرساخت پشتیبان: Corosync و Pacemaker
Masakari برای انجام وظیفه به یک گروه پشتیبان قدرتمند نیاز دارد. Corosync و Pacemaker نقش ستونهای زیرین این معماری را ایفا میکنند. Corosync پیامهای heartbeat را بین هاستها ردوبدل میکند تا وضعیت سلامت آنها مشخص باشد. Pacemaker نیز مانند یک مغز متفکر عمل میکند؛ وقتی هاستی پاسخی به heartbeat ندهد، Pacemaker متوجه میشود که مشکلی پیش آمده و آن هاست را موقتاً از چرخه خارج در نظر میگیرد. این اطلاعات سپس از طریق مکانیزمهای متمرکز به Masakari تحویل داده میشود تا فرآیند ریکاوری آغاز گردد.

ماژولهای Masakari: از رصد تا تصمیمگیری
- masakari-api: واسطی برای تعامل با کل سرویس
- masakari-engine: مغز متفکر که تصمیمهای اصلی برای ریکاوری را میگیرد و دستورات لازم را صادر میکند.
- masakari-hostmonitor: ناظر سلامت هاستها که هرگونه اختلال را گزارش میکند.
- masakari-instancemonitor: پایشگر سلامت ماشینهای مجازی.
تقسیمبندی زیرساخت به سگمنتها
ما زیرساخت ابری خود را در ماساکاری به چندین سگمنت (Segment) تقسیم کردیم، هر سگمنت شامل مجموعهای از هاستهای مشابه (از نظر سختافزار و نقش) بود. این سازماندهی باعث شد بتوانیم سیاستهای ریکاوری مختلفی را برای هر سگمنت تعریف کنیم. بدین ترتیب اگر هاستی در یک سگمنت دچار مشکل میشد، Masakari با توجه به سیاستهای همان سگمنت عمل میکرد.
هاستهای رزرو: ناجیان لحظات حساس
تصور کنید در شهری که زندگی میکنید، همیشه یک ایستگاه آتشنشانی آماده عملیات وجود دارد. هاستهای رزرو نیز چنین نقشی را برای ما ایفا میکنند. هر زمان یکی از هاستهای اصلی دچار مشکل میشود، هاست رزرو وارد عمل میشود و بار ماشینهای مجازی را به دوش میکشد.
سیاستهای ریکاوری و توسعه یک سیاست اختصاصی
Masakari بهصورت پیشفرض سیاستهای مختلفی برای ریکاوری ارائه میکند، مانند:
- Reserved_host: مهاجرت ماشینها به هاستهای رزرو شده، با تضمین منابع کافی.
- Auto: مهاجرت خودکار ماشینها به هر هاست در دسترس در همان سگمنت.
- Rh_priority: تلاش برای استفاده از reserved_host، و در صورت عدم موفقیت، بازگشت به Auto.
- Auto_priority: ابتدا تلاش برای Auto، و در صورت ناکامی، تلاش برای Reserved_host.
ما در این میان یک سیاست جدید توسعه دادیم که ترکیبی از Auto و Reserved_host بود. تفاوت این سیاست با سایرین در این بود که قبل از شروع فرآیند ریکاوری، یک هاست رزرو را همیشه فعال و آماده نگه میداشتیم تا از وجود فضای کافی در کلاستر مطمئن باشیم. این رویکرد انعطافپذیری Auto را با اطمینان خاطری که Reserved_host میدهد، ترکیب کرد.
TaskFlow: مدیر سناریوهای ریکاوری
یکی از جذابترین قابلیتهای Masakari، استفاده از TaskFlow است. TaskFlow همچون یک کارگردان ماهر، صحنهپردازی عملیات ریکاوری را برعهده دارد. ما با استفاده از TaskFlow توانستیم گام به گام مشخص کنیم که در هنگام بروز خرابی، چه وظایفی انجام شود و ترتیب آنها چگونه باشد. این وظایف در سه مرحله تعریف شدند:
- Pre Tasks (پیش وظایف):
این مرحله شامل اقداماتی است که قبل از آغاز ریکاوری اصلی انجام میشود: - خط قرمز: بررسی تعداد نوتیفیکیشن های فعال
ابتدا کمی صبر میکنیم و وضعیت اعلانهای اخیر را بررسی میکنیم. اگر تعداد اعلانهای خرابی در مدت زمان مشخصی بیش از حد باشد، نشانه آن است که مشکل جدی است. در این صورت، جابهجاییها متوقف شده و هاست در حالت تعمیر باقی میماند تا از اقدامات غیرضروری جلوگیری شود. اگر این تسک پاس نشود، کلا فرآیند ریکاوری متوقف میشود. - بررسی اینترفیسهای شبکه
در این تسک وضعیت ارتباطات شبکه هاست از سورسهای مختلف بررسی میشود. اگر شبکه پایدار باشد، ریکاوری متوقف و هاست از حالت `در انتظار تعمیر` خارج میشود، زیرا ظاهراً مسئله حل شده است. اما اگر هیچ کدام از اینترفیس های هاست پاسخگو نباشند و این اختلال در چندین منبع مختلف تأیید شود، مسیر ریکاوری ادامه مییابد. - غیرفعال کردن هاست در کلاستر
برای جلوگیری از استقرار ماشینهای مجازی جدید روی هاست مشکلدار، سرویس Nova آن هاست غیرفعال میشود. این کار از بدتر شدن شرایط جلوگیری میکند.
هدف از Pre Tasks این است که مطمئن شویم هر اقدام بعدی درست و بهجا است و بیمورد سراغ جابهجایی یا تغییر زیرساخت نرویم.
- Main Tasks (وظایف اصلی):
این مرحله قلب عملیات ریکاوری است و شامل اقداماتی است که برای بازگرداندن سرویس به حالت پایدار انجام میشوند. برای مثال: - آمادهسازی ماشینهای مجازی:
ماشینهای مجازی که نیاز به جابهجایی، توقف یا قرارگیری در حالت خاصی دارند، پیش از آغاز عملیات مشخص میشوند. این کار کمک میکند در طول ریکاوری، دقیقاً بدانیم با هر ماشین چه باید کرد. - اطلاعرسانی به کاربران:
برای آنکه کاربران از شرایط باخبر باشند، به آنهایی که پیش از خرابی، سرویس فعال داشتند، پیام اطلاعرسانی ارسال میشود. این کار اعتماد و آگاهی کاربران را حفظ میکند. - فعال کردن هاست رزرو:
برای اطمینان از وجود منابع کافی در هنگام جابهجایی، یک هاست رزرو نیز در کلاستر فعال میشود. این هاست در واقع مثل نیروی کمکی عمل میکند تا در صورت کمبود منابع، ماشینهای مجازی بتوانند به آن منتقل شوند. - جابهجایی ماشینهای مجازی:
در این تسک ماشینهای مجازی از هاست معیوب به سایر هاستها منتقل میشوند. اگر ماشینی در حالت نامناسبی باشد، ابتدا مشکلات آن برطرف شده و سپس جابهجا میشود. اگر حین جابهجایی خطایی رخ دهد، ماشینهای مشکلدار شناسایی و تلاش مجدد انجام میشود. در پایان، اگر ماشینی روی هاست معیوب باقی مانده باشد، فهرست آنها ثبت میشود تا در مراحل بعدی رسیدگی شوند.
در این بخش، TaskFlow مراحل را بهصورت ترتیبی و با در نظر گرفتن وابستگیها اجرا میکند.
- Post Tasks (وظایف پس از ریکاوری):
وقتی جابهجاییها کامل شد و سرویسها به ثبات رسیدند، نوبت به اقدامات نهایی میرسد.
- بازگرداندن هاست رزرو به حالت اولیه:
هاست رزروی که فعال شده بود، دوباره غیرفعال و برای استفاده در سناریوهای بعدی آماده میشود.
در انتهای این فرآیند، هاست معیوب در حالت تعمیر باقی میماند تا نیروی فنی مشکل اصلی آن را برطرف کرده و هاست را مجدداً به چرخه عملیاتی بازگرداند. با این رویکرد چندلایه، Masakari کمک میکند تا فرآیند ریکاوری هوشمند، مرحلهبهمرحله و با کمترین تأثیر منفی بر کاربران و زیرساخت انجام شود.
یکی دیگر از چالشهای جالبی که هنگام استفاده از سرویس Masakari در کلاستر با آن مواجه شدیم، حفظ وضعیت (State) ماشینهای مجازی قبل از ریبوت یک هاست بود. چرا؟ چون به محض اینکه هاست ریبوت میشد و سرویس nova-compute دوباره بالا میآمد، همه ماشینهای مجازی به حالت خاموش (ShutOff) تغییر وضعیت میدادند. بدتر از آن؟ دیگر نمیشد از اکشن Evacuate استفاده کرد، بنابراین اگر عملیات ریکاوری یک هاست در میانه راه بود، از لحظه بوت شدن هاست مشکل دار، دیگر هیچ ابرکی امکان جابه جایی نداشت.
برای رفع این چالش، راهحل خلاقانهای پیادهسازی کردیم: یک systemd service unit ساده اما هوشمند که روی Compute Nodes مستقر میشود، پیاده سازی کردیم. وظیفه اصلی این سرویس چیست؟ اگر یکی از هاستها ریبوت شود، سرویس بهصورت خودکار nova-compute را در حالت Down نگه میدارد تا بتوانیم بدون دردسر وضعیت ماشینهای مجازی را مدیریت کنیم.
این سرویس مثل یک نگهبان عمل میکند که میگوید: "نه! تا وقتی که مطمئن نشدم همه چیز سر جای خودش است، nova-compute نمیتواند وارد عمل شود." با این کار، نهتنها از تغییر وضعیت ماشینها جلوگیری کردیم، بلکه امکان استفاده از اکشن Evacuate را نیز حفظ کردیم. یک راهحل ساده، اما موثر برای یک مشکل اساسی!
نتیجه: کاهش چشمگیر داونتایم
پس از استقرار Masakari، تنظیم سیاستهای جدید، و توسعه هوشمندانه TaskFlow، داونتایم کاربر به طرز چشمگیری کاهش یافت. در بسیاری از سناریوها، به جای چندین ساعت، تنها در حد چند دقیقه اختلال داشتیم. به طور میانگین، با استفاده از سیاستهای جدید و معماری TaskFlow، ما توانستیم داونتایم را درصد زیادی نسبت به قبل کاهش دهیم؛ همچنین لود کاری و استرس رو برای نفر آنکال تیم کاهش دادیم. کاری که برای ما، در دومین سالگرد استقرار Masakari، یک موفقیت بینظیر بود.
پایان خوش داستان
Masakari برای ما همان قهرمانی بود که بیسروصدا پشت صحنه کار میکنه. هر زمان هاستی دچار مشکل میشه، Masakari وارد عمل میشه: هاست رزرو فعال میشه، ماشینهای مجازی بیدرنگ منتقل میشوند، کاربران مطلع میشوند، و در نهایت، سرویسها در کوتاهترین زمان ممکن به روال عادی برمیگردند و ما با خاطری آسودهتر به ادامه کار میپردازیم.
این تجربه نشان داد که با ابزارهای مناسب، برنامهریزی هوشمندانه، و مکانیزمهای خودکارسازی مانند Masakari و TaskFlow، میتوان داونتایم را به حداقل رساند و اعتماد را به فضای ابری بازگرداند. در دنیایی که هر ثانیه اهمیت دارد، این سرمایهگذاری برای ما ارزشمند بود و دومین سالگرد استقرار Masakari گواهی است بر موفقیت این رویکرد.
مطلبی دیگر از این انتشارات
توسعه نرمافزار چابک با نگاه «محصولمحور»
مطلبی دیگر از این انتشارات
مدیریت حادثه؛ بخش دوم: آمادگی برای حادثه
مطلبی دیگر از این انتشارات
چگونه با حذف حافظه مشترک، صدها هزار درخواست در ثانیه را پردازش کردیم