

سالک .[ ل ِ ] (ع ص ، اِ) مسافر و راه رونده. / a3dho3yn.ir
مدیریت حادثه؛ بخش سوم: پاسخ به حادثه
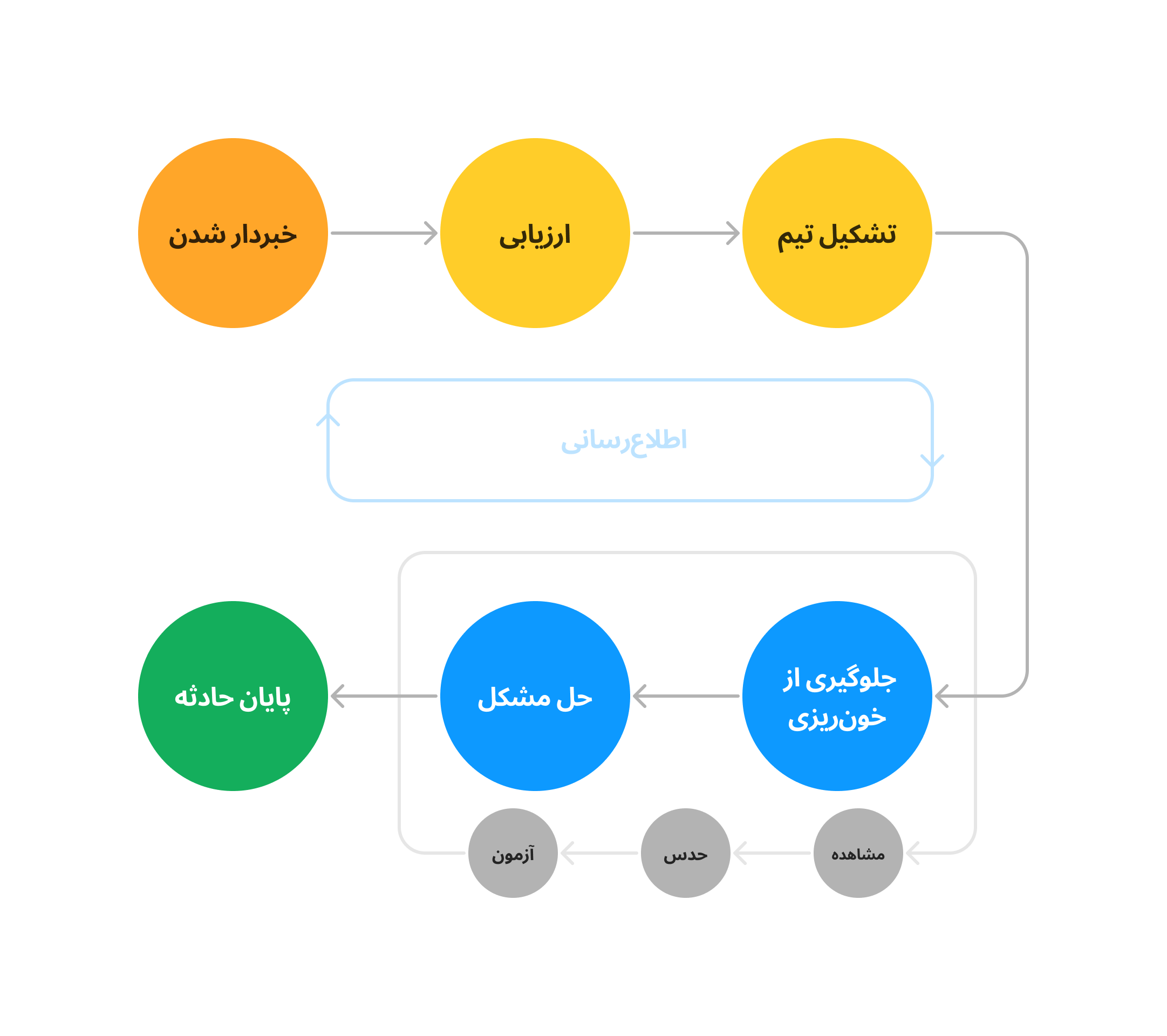
حوادث، به خصوص حوادث بزرگ، میتونن همهچیز رو به هم بریزن و شما رو سردرگم کنن. یه ساختار و فرآیند ازپیش توافق شده و قواعدی برای ارتباط و هماهنگی کارها، میتونه آشوب و بینظمی رو کم کنه و به افراد کمک میکنه در زمان حادثه تمرکزششون روی حلوفصل مشکل باشه. در این قسمت از مجموعه مدیریت حادثه، به مراحل پاسخ به حادثه میپردازیم.
۱. خبردار شدن
با خبردار شدن از حادثه، باید نفر کشیک (on-call) رو براساس شیفتبندی و قواعد تعریف شده، فراخوانی (page) میکنیم و اگر در زمان مناسب (طبق قاعده از پیش تعریف شده) پاسخ نداد، سراغ پشتیبان و نفرات بعدی میریم. به علاوه، باید در ابزاری که از پیش توافق کردیم، حادثه رو ثبت کنیم:
- خلاصه مشکل (در عنوان)
- شرح مشکل و تاثیر روی مشتری
- محصولاتی یا سیستمهایی که تحت تاثیر قرار گرفتند
- تخمین اولیه از اولویت (براساس جدولی که در بخش ارزیابی آمده).
- گزارشکننده و/یا منبع شناسایی (مانیتورینگ، تیکت، …)
در حالت ایدهآل، ابزارهای مانیتورینگ و هشداردهی، قبل از اینکه حتا مشتریان متوجه بشن، ما رو از حادثه باخبر میکنن. ولی ممکنه همه چیز مطابق انتظار پیش نره و مشتری(ها) یا همکاران متوجه مشکل بشن. به همین خاطر لازمه یک مسیر غیرسیستمی برای به صدا درآوردن آژیر تعریف کنین.
ثبت حادثه و فراخوانی افراد تا حد خوبی میتونه خودکار انجام بشه:
— حادثههایی که به صورتی سیستمی و با alert از وجودشون مطلع میشیم، با یک روال خودکار (Automation) میتونن در ابزار مدیریت حادثه ثبت بشن.
— سیستم پشتیبانی مشتریان (Ticketing) رو میتونین به ابزار مدیریت حادثه متصل کنین تا با یک کلیک بشه از اطلاعات تیکت، حادثه جدید تعریف کرد
— برای پیامرسان سازمانیتون میتونین یه ربات بنویسین که امکان تعریف حادثه با یه دستور و/یا از روی یک پیام داشته باشه.
— ابزار مدیریت حادثه، به محض ثبت حادثه افراد رو طبق قاعدهای که تعریف کردین (Escalation Policy)، فراخوانی میکنه (و لازم نیست شما توی جدولها و شماره تلفنها، دنبال افراد باشین)
پس از ثبت حادثه، تمامی افراد شرکت باید بتونن ببینن که حادثه (بالقوهای) در جریانه. این کار کمک میکنه تا گزارش تکراری کمتر بشه، یا اگر تیم دیگهای دچار مشکل شده، بتونه ببینه که یکی از دلایل احتمالی میتونه این حادثه باشه. علاوه بر رویتپذیر بودن حادثه، اگر تیکتی مربوط به این حادثه ثبت شد شناسهی این حادثه رو به برچسبهای (tag) تیکت اضافه میکنیم.

۲. ارزیابی (اولویتبندی)
مهندس کشیک بعد از تایید اطلاع از حادثه و پیش از انجام هر کار دیگه (از جمله دستبهکار شدن برا حل مشکل!)، باید سطح حادثه رو ارزیابی کنه. این کار کمک میکنه بدونیم با چه فوریتی و چطور باید به حادثه واکنش نشون بدیم. برای مثال، ممکنه تصمیم بگیریم نفرات بیشتری رو خبر کنیم، یا کار پرریسکتری رو (نسبت به شرایط غیرجنگی) برای جلوگیری از گسترش مشکل انجام بدیم، یا اصلاً ببینیم مشکل حادی نیست و تصمیم بگیریم رسیدگی به مشکل رو در روز کاری بعد انجام بدیم.
قاعده کلی برای تعیین سطح/اولویت اینه که بدبینانه انتخاب میکنیم. هرجایی شک داشتین یا اطلاعات کافی نداشتین، اولویت بالاتر (و حالت بدتر) رو در نظر بگیرین.
برای تعیین سطح، راهکارهای مختلفی هست. میتونین در ابتدا با یه مدل خیلی ساده شروع کنین و فقط حادثههای رو به کوچک/بزرگ (Minor/Major) تقسیم کنین، یا از الگوهای موجود (مثل AWS و PagerDuty) استفاده کنین. مهمتر از اینکه از چه چارچوبی استفاده میکنین، اینه که برای همه قابل فهم (و استفاده) باشه و همهی تیمها از یک چارچوب مشترک استفاده کنن (تا رویکرد یکپارچهای در رابطه با مشتری داشته باشین).
ما در آروان از چارچوبی مشابه ITIL استفاده میکنیم. در این چارچوب، دو شاخص فوریت و تاثیر کمک میگیریم و از خودمون میپرسیم:
- چه تعداد مشتری یا همکار تحت تأثیر قرار گرفتن؟ چه اثری روی اونها داره؟ آیا جنبههای دیگهای مثل امنیت، روابط عمومی، یا از دست رفتن داده وجود داره؟
- چه زمانی شروع شده؟ چقدر سریع داره گسترش پیدا میکنه؟ زمان تخمینی رفع اون چقدره؟
بعد با با ترکیب این دو شاخص، اولویت حادثه رو مشخص میکنیم.

۳. شروع رسیدگی با دور هم جمع کردن تیم حادثه و اطلاعرسانی اولیه
بعد از ارزیابی، رسیدگی به حادثه شروع میشه. در این زمان، باید افرادی که برای حل مشکل به حضورشون نیاز داریم رو دور هم جمع کنیم و اولین اطلاعرسانی به مشتریان رو انجام بدیم (برای جزییات بیشتر، بخش اطلاعرسانی رو ببینید).
برای تسهیل ارتباط افراد با هم، همزمان از دو مسیر استفاده میکنیم:
- گفتگوی متنی (Chat): برای این کار، یه کانال در پیامرسان سازمانی ایجاد میکنیم که اسمش، شناسه حادثهست و در توضیحاتش، خلاصه و اولویت حادثه، افراد و نقشهاشون و لینک به حادثه قرار میگیره. مشاهدات، تصمیمها و اقدامات (یا تغییرات) باید از طریق گفتگوی متنی به اشتراک گذاشته بشه تا زمانها مشخص باشه.
- تماس تصویری (Video Call)
برای حادثههای گستردهتر، توصیه میشه یک صفحه «وضعیت حادثه» در ابزار مدیریت مستندات (مثل Google Docs یا Confluence) ایجاد کنید و در اون خلاصهای از مشکل، حدسهای آزموده و راهحلهای در حال اجرا، و تغییرات اعمال شده (شامل اینکه چه کسی، چه زمانی چه چیزی رو تغییر داده و چطور باید برگردونده بشه) رو ثبت کنین.
مثل همیشه، بخشی از این کارها (مثل ایجاد کانال و سند) میتونه خودکار انجام بشه. هرچی بیشتر خودکارسازی کنین، بهتر میتونین به اصل کار (که قابل خودکار شدن نیست!) برسین.
۴. جلوگیری از خونریزی و برطرف کردن مشکل
از اینجا به بعد ما در یک چرخه هستیم؛ چرخه مشاهده، حدس و آزمودن:
- شواهد رو بررسی میکنیم و میبینیم چه اتفاقی داره میافته،
- به حدس/نظریهای درباره اینکه چرا این اتفاق میافته (و چه اقدامی احتمالاً برطرفش میکنه) میرسیم
- راهحل رو (با تایید فرمانده) به کار میبندیم
- اگر مشکل حل نشد، دوباره شواهد رو بررسی میکنیم
در این چرخه، اولویت اولمون باید جلوگیری از گسترش مشکل و/یا حل سریع اون باشه که بهش «بندآوردن خونریزی» میگیم. در اینجا، بهدنبال اقدامات سریعی مثل جدا کردن از شبکه (درمورد نفوذ و حادثههای امنیتی)، برگرداندن نسخه (وقتی نسخه جدیدی منتشر شده که حدس میزنیم مشکلزاست)، اعمال محدودیت روی درخواستها (وقتی افزایش ناگهانی در ورودی داریم) و نظایر اینها هستیم.
هشدار: در بهکارگیری اقدام سریع و انقلابی بسیار مراقب باشید؛ چون ممکنه با اقدام اشتباه آسیب رو بیشتر کنین.
بعد از تسکین مشکل و/یا بندآوردن خونریزی، با بررسی دقیقتر مشکل اصلی رو پیدا و رفع میکنیم و بعد از اطمینان از برطرف شدن مشکل، تغییرات موقتی که در این میان انجام دادیم رو برمیگردونیم (مثل اتصال مجدد به شبکه، انتشار نسخه یا برداشتن محدودیت). پایان حادثه زمانیه که سرویس به وضعیت قبل از حادثه برگرده.
در کل فرآیند، بدون اجازه فرمانده هیچ کاری انجام ندین و دستورات فرمانده رو اجرا کنین. فرمانده قبل از هر تصمیمگیری نظرات رو میپرسه و اون زمان اگر مخالفتی دارین میتونین اعلام کنین.
علاوه بر مدیریت چرخه حل مشکل، فرمانده باید در طول مدت حادثه از انجام نقشها و مسئولیتها در زمان حادثه اطمینان حاصل کنه. از جمله:
- ارزیابی سطح حادثه به صورت دورهای
- فراخوانی (page) افراد بیشتر در صورت نیاز (یا بالعکس، مرخص کردن افرادی که دیگه به حضورشون نیازی نیست). با حضور افراد جدید، فرمانده باید به هر کسی یک نقش بده و مطمئن بشه که میدونه چه مسئولیتی داره.
- اطلاعرسانی به ذینفعان داخلی و خارجی اطلاعرسانی
برای اینکه کارهایی که در زمان حادثه باید انجام بدیم رو فراموش نکنیم، یه چکلیست یه صفحهای از این موارد درست کردیم که شامل مراحل و فهرست کارهایی که باید در هر مرحله انجام بدیم میشه. چکلیست جای خواندن این شیوهنامه و/یا آموزش رو نمیگیره. فقط قرار کمک کنه چیزی به خاطر فراموشی از قلم نیافته.
گفتگوها در زمان حادثه
در طی فرآیند پاسخ به حادثه، خیلی مهمه که اطلاعات و دستورات به درستی منتقل بشن. به همین خاطر:
- واضح و شفاف صحبت میکنیم
- از اختصاری صحبت کردن پرهیز میکنیم (مگر اینکه از پیش توافقی روی اختصارها شده باشه)
- با تکرار دستوری که دریافت کردیم (و کاری که قصد انجامش رو داریم)، از صحت برداشت مطمئن میشیم
در مستندات PagerDuty میتونین راهنماییهای با جزییات بیشتری برای تماس و گفتگو در زمان حادثه پیدا کنین.
راهنمای اطلاعرسانی
کجا اطلاعرسانی کنیم؟
دو کانال مجزا برای اطلاعرسانی داخلی و خارج از سازمان داریم:
- اطلاعرسانی داخلی از طریق کانال حوادث و/یا ایمیل به گروه حادثه (شامل مدیرهای محصولها و تیمها و هر کسی که علاقهمنده) انجام میشه.
- اطلاعرسانی به مشتریان به طور معمول از طریق صفحه وضعیت (Status Page) و توسط تیم پشتیبانی (مشتریان) انجام میشه. در موارد حیاتی، ممکنه علاوه بر صفحه وضعیت، از طریق پیامک و/یا ایمیل هم به مشتریانی که تحت تاثیر این حادثه قرار میگیرن، اطلاعرسانی کنیم.
ابزارهای Status Page اغلب امکان ارسال اخبار به ایمیل و پیامرسان (مثل اسلک، مایکروسافت تیمز و…) به مشتریان دارن و افراد میتونن subscribe کنن. همچنین این امکان رو میدن که اطلاعرسانیها رو همزمان روی شبکه اجتماعی (مثل توییتر) بفرستین.
چهوقت اطلاعرسانی کنیم؟
اطلاعرسانی اولیه، بلافاصله بعد از اطمینان از وجود مشکل (و درست بودن خبر حادثه) انجام میشه. اهمیت اطلاعرسانی در اولین فرصت اینه که به مشتریان اعلام کنیم از حادثه خبرداریم و داریم با اولویت بالا بهش رسیدگی میکنیم.
اطمینان از وجود مشکل، لزوماً توسط مدیر حادثه انجام نمیشه. برای مثال، در آروان، تیم NOC با مشاهده مشکل روی مانیتورینگ و/یا مشاهده تاثیر روی سرویسها، اطلاعرسانی اولیه رو انجام میده.
بعد از به جریان افتادن فرآیند پاسخ به حادثه هم باید در فواصل منظم (متناسب با اولویت حادثه) کارکنان و مشتریان رو در جریان کار قرار بدیم. حتی اگر اطلاعات تازهای نداریم، همین رو اعلام میکنیم (با این توضیح که داریم روی پیدا کردن حل مشکل کار میکنیم و نیاز به زمان بیشتری هست)
چطور اطلاعرسانی کنیم؟
برای سرعت در اطلاعرسانی، از قالبهای اطلاعرسانی از پیش آماده شده استفاده میکنیم. همچنین نقشهای از وابستگی سرویسها تهیه کردیم که با مشخص کردن یک سرویس (مثل CDN) نشون میده چه سرویسهای دیگهای تحت تاثیر قرار میگیرن (و حادثه باید برای همه این سرویسها ثبت بشه).
اطلاعرسانی به مشتریان باید مختصر و مفید باشه. مشتریهای بیرونی اغلب به جزئیات فنی علاقهمند نیستن، فقط دوست دارن بدونن مشکل برطرف شده؟ اگر برطرف نشده، در چه مرحلهای هستیم و کی برطرف میشه؟
اطلاعرسانی در مراحل مختلف در یکی از این دستهها قرار میگیره:
- New Issue: اطلاعرسانی اولیه و اعلام حادثه
- Investigating: زمانی که هنوز درحال بررسی علت مشکل هستیم
- Update: زمانی که خبر جدیدی بهدست آوردیم
- Monitoring: زمانی که اصلاحی انجام دادیم و در حال پایش برای اطمینان از برطرف شدن مشکل هستیم
- Resolved: رفع کامل مشکل و پایان حادثه
اطلاعرسانیهای داخل سازمان با این قالب انجام میشه:
- شروع با یک یا دو جمله از وضعیت فعلی حادثه و میزان تأثیر روی مشتریان
- بخش «وضعیت فعلی» شامل ۲-۴ مورد
- بخش «قدمهای بعدی» شامل ۲-۴ مورد
- علت اصلی و زمان تخمینی از رفع مشکل
- چه زمانی اطلاعرسانی بعدی انجام میشه
قبل از ارسال بررسی میکنیم که آیا همه این موارد رو اعلام کردیم یا نه. حتی اگر موردی معلوم نیست، به جای حذف مورد، مینویسیم نمیدانیم/مشخص نیست.
اینجا به پایان قسمت سوم و فرآیند پاسخ به حادثه میرسیم. تا اینجا، با برداشتن قدمهای آمادگی برای حادثه و پاسخ درست، میتونیم هزینه حادثه رو کاهش بدیم. حالا نوبت اینه که بتونیم از این هزینهای که پرداخت کردیم، بیشترین بهره رو ببریم. این کار با انجام کالبدشکافی و کارهای پس از حادثه انجام میشه که در قسمت بعد بهشون میپردازم.
برای عمیقتر شدن در موضوع، پیشنهاد میکنم مستندات پاسخ به حادثه PagerDuty و مدیریت حادثه در گوگل (و اینجا)رو ببینید. در قسمت ۱۳ از پادکست پیمان فخاریان هم جواد علیپناه مراحل عیبیابی و رفع مشکل رو بر مبنای کتاب SRE گوگل و با مثالهای عملی توضیح میده که توصیه میکنم بشنوین.
مطلبی دیگر از این انتشارات
گاهشمار رنجهای مکرر؛ فیلترینگ چطور تو محصول حادثه آفرید
مطلبی دیگر از این انتشارات
مانیتورینگ متریک های دامنه: مانیتورینگ با قابلیت جدید CDN ابر آروان
مطلبی دیگر از این انتشارات
Distributed Tracing And Jaeger